true
Mehr lesenTMUX
Ich hatte da mal einen Post auf reddit geesehen und mir gedacht, das klingt soch irgendwie nach einem Plan. Mit dem neuen Rechner den ich bekommen habe war das eine gute Gelegenheit. Hier kann ich in einem Terminal Fenster alle Prozesse offen halten, die ich so brauche, oder an denen ich schon mal Spass habe.
Timewarrior / Taskwarrior
Die beiden Programme verwende ich um per CLI mal eben schnell einen Task zu erstellen, zu starten oder zu beenden. In der Kombination mit Timewarrior habe ich dann auch noch ein Tool, dass die Zeiten speichert, die ich für einzelne Tasks oder die verschiedenen Projekte aufgewndet habe.
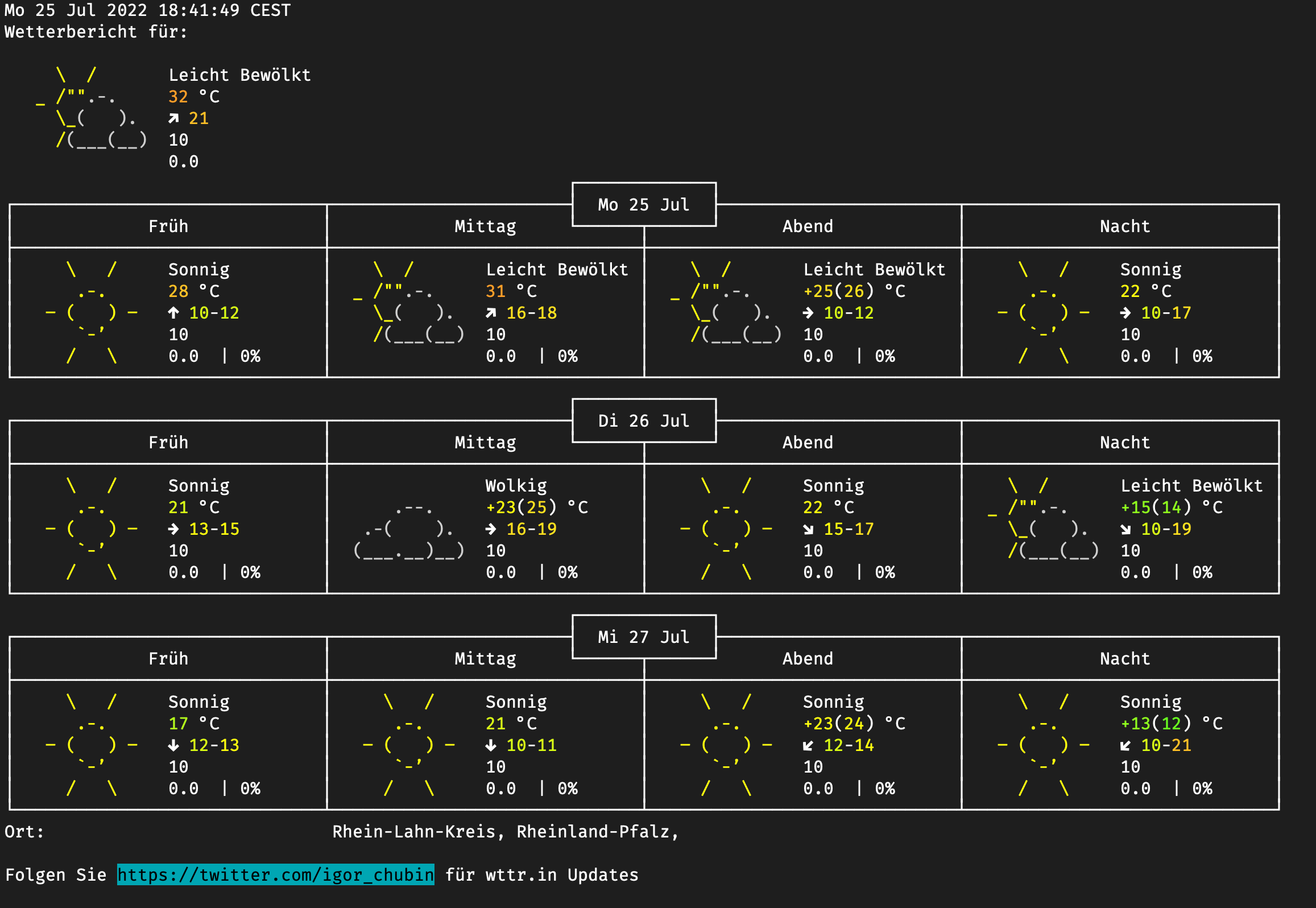
wttr.in
Man muss doch immer das Wetter ein bisschen im Blick habe.
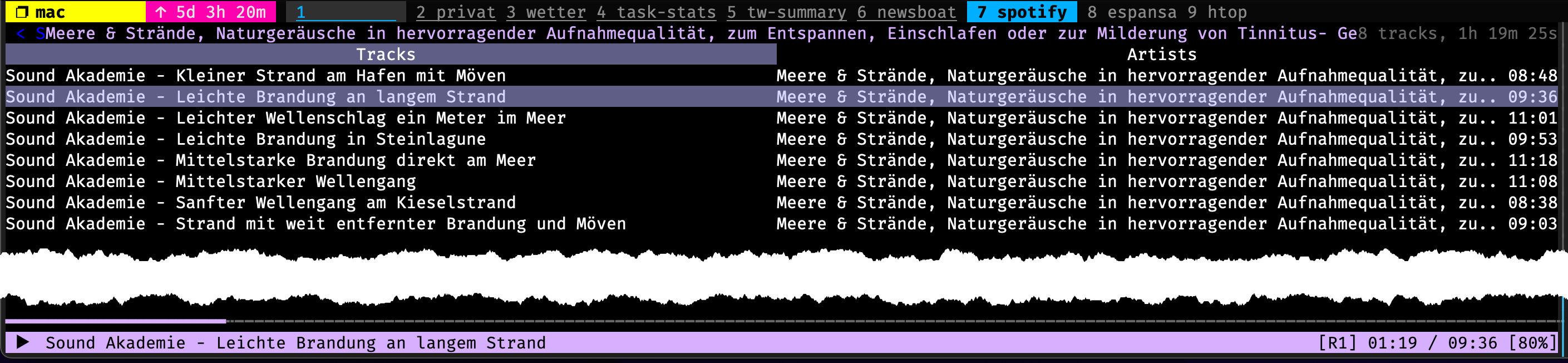
NCSPOT
Spotify in der CLI? Ja klar, hast Du schon mal geschaut wie viel Speicher Spotify sich reserviert? Ich habe aktuell nur 32 Gig, da muss ich ein wenig haushalten.

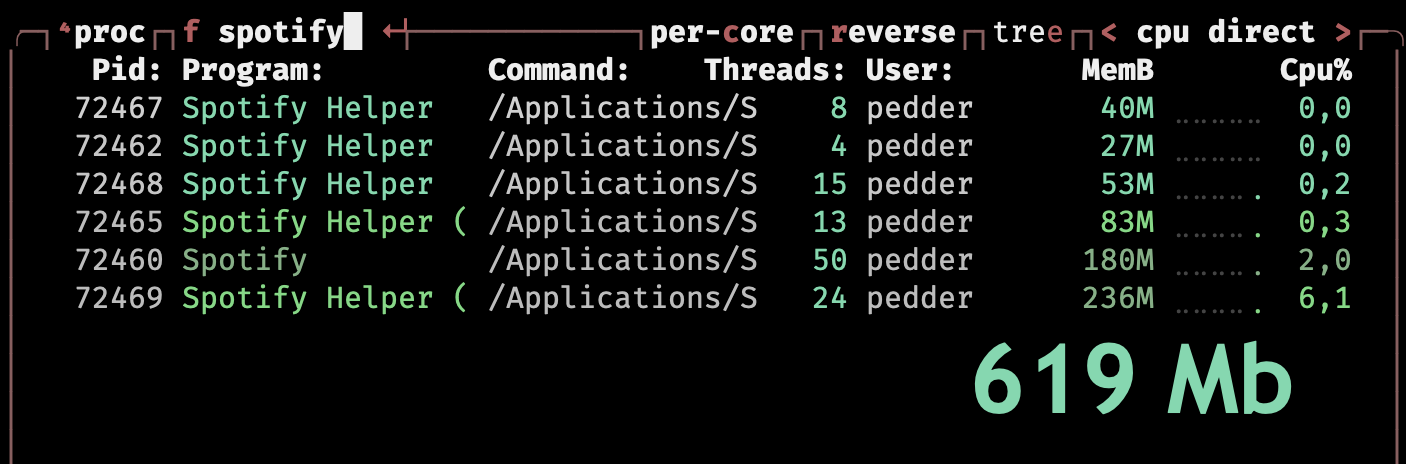
Ich hatte hier gestern erst 70 MB Speicherverbrauch, die 106 heute erscheinen mir ein bisschen viel.
Nachtrag
Wusste ich doch, das der Speicherverbrauch eigentlich total niedrig ausfällt:

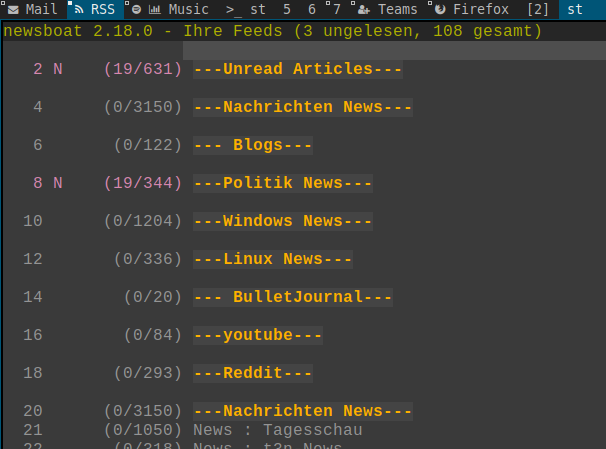
Newsboat RSS Reader
Noch bin ich nicht dazu gekommen mir emacs einmal genauer anzuschauen, außerdem will ich nicht schon wieder ein Fass ohne Boden aufmachen.
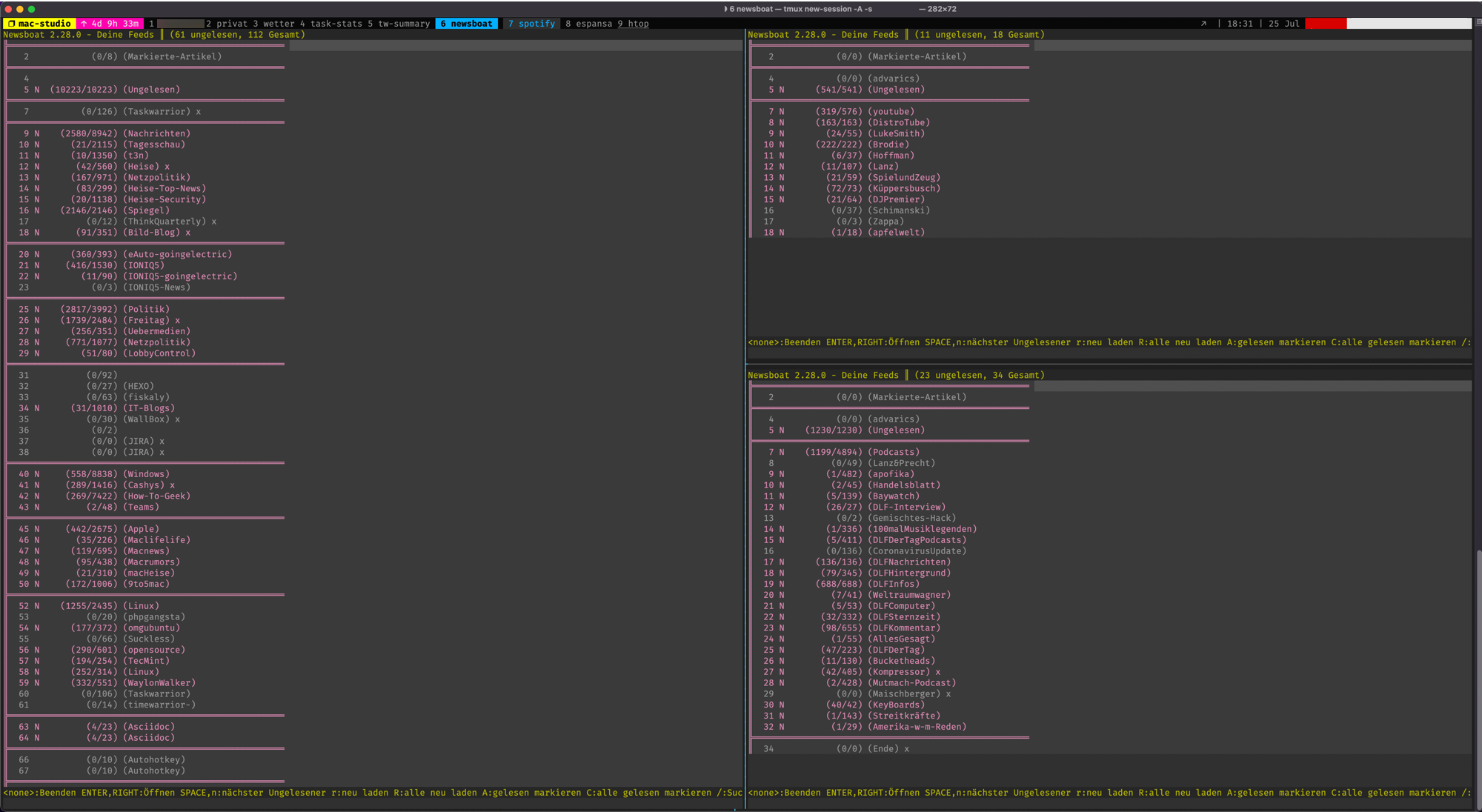
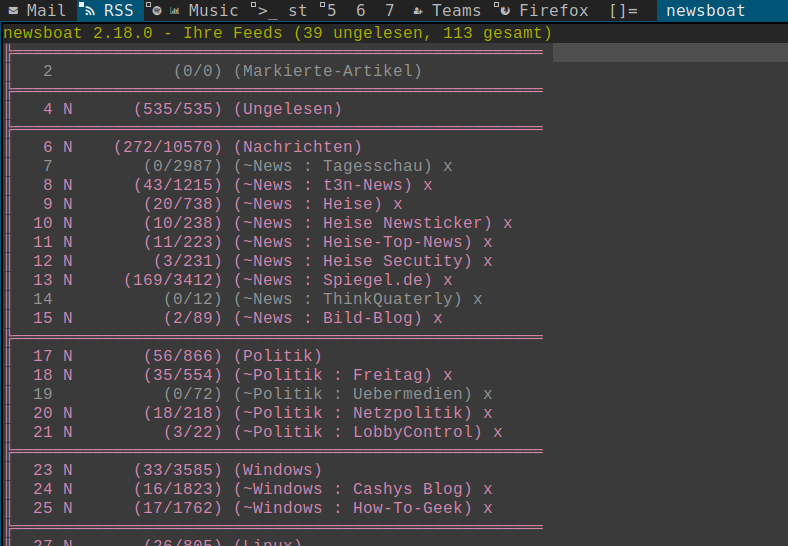
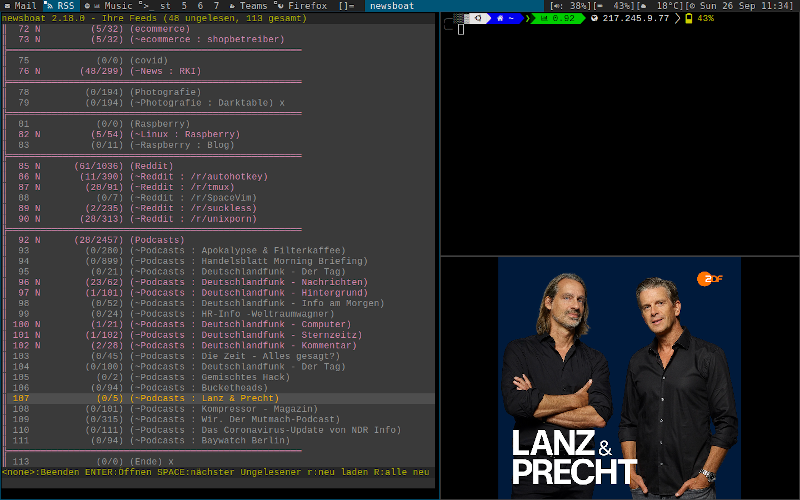
Was ich an newsboat so mag ist, dass ich hier mit tmux, in 3 Fenstern ein wenig sortiert meine wichtigsten RSS-Feeds im Blick halten kann. Ich habe 3 verschiedene Config-Dateien hinterlegt und kann so meine RSS-Feeds, meine youtube-Feeds und meine wichtigsten Podcasts im Blickbehalten. Mit mpv kann ich Mediendateien abspielen, also Podcasts oder Videos und überall wo das nicht funktioniert, wird per URL-View einfach der Standard Browser vom System aufgerufen.
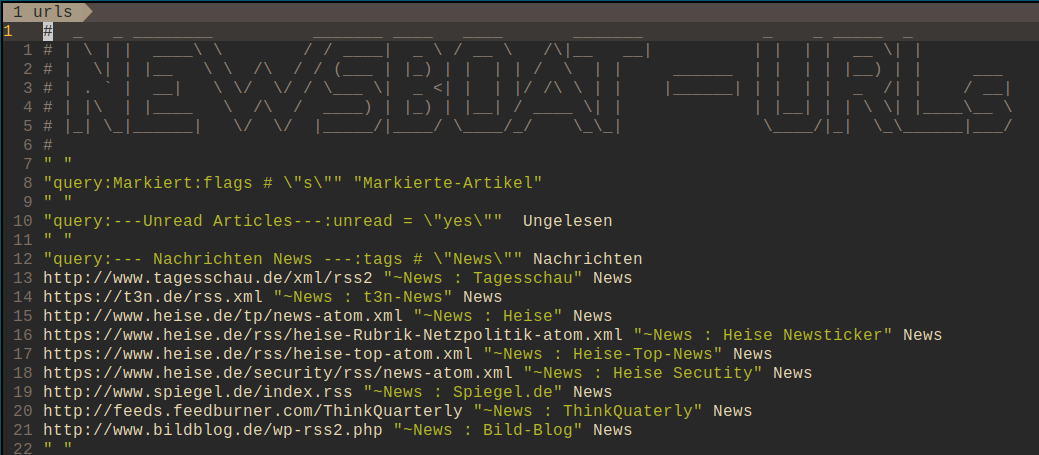
Nur falls jemand ein bisschen was abschauen will:
# _ _ ________ _______ ____ ____ _______ # | \ | | ____\ \ / / ____| _ \ / __ \ /\|__ __| # | \| | |__ \ \ /\ / / (___ | |_) | | | | / \ | | # | . ` | __| \ \/ \/ / \___ \| _ <| | | |/ /\ \ | | # | |\ | |____ \ /\ / ____) | |_) | |__| / ____ \| | # |_| \_|______| \/ \/ |_____/|____/ \____/_/ \_\_| # # browser $BROWSER save-path "~/Dokumente/rss-feeds-worth-saving/" download-path ~/Musik player "mpv" # # add video or audio to play queue using mpv (requires: task-spooler, mpv, youtube-dl) # task-spooler: https://www.youtube.com/watch?v=wv8D8wT20ZY # youtube-dl: https://www.youtube.com/watch?v=MFxlwVhwayg macro p set browser "mpv --ontop --no-border --force-window --autofit=500x280 --geometry=-15-10 %u"; open-in-browser ; set browser "$BROWSER %u" refresh-on-startup yes auto-reload yes reload-time 30 reload-threads 100 external-url-viewer "urlview" # external-url-viewer "urlscan" bind-key U show-urls # max-items 100 confirm-delete-all-articles yes scrolloff 25 # notify-xterm yes suppress-first-reload yes display-article-progress yes confirm-mark-all-feeds-read yes confirm-mark-feed-read no # error-log ~/.local/share/newsboat/error.log #https://gitlab.com/dj-bauer/newsboat-rice/-/blob/master/config highlight feedlist "[╒╘╞]═.*═[╛╕╡]" color175 color237 #yellow default bold highlight feedlist "[║│]" color175 color237 bold #yellow default bold highlight feedlist "╠═.*" color175 color237 bold #yellow default bold # highlight feedlist "\\(youtube\\) .*" red # highlight feedlist "\\(Reddit\\) .*" green # highlight feedlist "\\(Podcast\\) .*" magenta # highlight feedlist "\\(Blogs\\) .*" cyan # highlight feedlist "\\(Reddit\\) .*" color166 feedlist-format "%?T?║%4i %n %14u (%T) %S &╠════════════════════════════════════════════════════%t?" feedlist-title-format "%N %V - Deine Feeds ║ (%u ungelesen, %t Gesamt)%?T? - tag ’%T'&? " # keybindings because of muscle memory. bind-key SPACE next-unread bind-key j down bind-key k up bind-key g home bind-key G end bind-key RIGHT open bind-key U show-urls